I'm going to cut to the chase in case somebody finds this post searching for a solution to this problem: try a different USB cable.
Okay, so now that I've gotten the actual solution out of the way, a little bit of background on how I got there.
I use Arch Linux on the PC in my living room, which is my primary gaming device. A couple of years back I was having trouble with Bluetooth connectivity and I bought a couple of cheap 15' USB A-to-C cables on Amazon.
(By the way, I have a simple "try this first" recommendation for Bluetooth connectivity issues in Linux, too: rmmod btusb && modprobe btusb)
Up until this point those USB cables worked great. I've used them with an Xbox controller and various 8bitdo controllers and never had any issue.
Last month I picked up a DualSense controller, because I heard it's got some advanced features that certain first-party Sony games like Horizon Forbidden West and Ghost of Tsushima (and a few third-party games like Final Fantasy 7 Remake Intergrade) use.
So I fired up Horizon Forbidden West and instead of haptic feedback I got this godawful crackling audio out of my controller.
And I've never actually used a DualSense controller before, but it pretty clearly wasn't supposed to sound like that.
So, okay, it was the USB cable, and I've already told you it was the USB cable. But I didn't figure that out right away. As a Linux user, I have spent the past twenty years training myself to assume that any given issue I have with my computer is some weird Linux problem.
I did some reading. It seems that DualSense features are supported in Steam Play and work just fine on a Steam Deck.
But just because something works on the Deck doesn't mean it's going to work on my particular desktop Linux setup. As any PC gamer will tell you, there's a world of difference between a single hardware target and the countless variables of a general-purpose PC.
So I set to work, trying to figure out if it was a problem with Pipewire, or Proton, or my udev rules, or what.
It wouldn't be entirely accurate to say I spent weeks on it. It did take me weeks to figure it out, but it's not like I was working on it consistently. I have a job, a one-year-old, and not a whole hell of a lot of free time, and those times I did manage to spend some time troubleshooting the controller, after awhile I'd say "fuck it" and just play the damn game for awhile. (And if the audio crackling got to be too distracting, well, I could always just use a different controller. Or play a different game.)
But finally, scouring DuckDuckGo results for other posts by people who'd had similar problems, I found a Reddit post where somebody suggested trying a different USB cable.
And well, you know that fixed it because I already told you that back in the first sentence of this post.
I looked back at the Amazon listing for the USB cables I'd bought. The brand is iSeekerKit and the first thing I noticed is that it explicitly mentions they work with PS5 controllers. But on closer inspection I note that the listing specifically describes them as "Charger for PS5 Controller". It doesn't say anything about being a data cable for a PS5 controller. Pretty sneaky, iSeekerKit.
Anyway, I've ordered a new pack of 15' USB A-to-C cables, from a brand I've actually heard of (JSAUX). We'll see how they do.
I keep thinking of that new EU regulation requiring devices to standardize on USB-C for their charging connectors, and boy, they're gonna be mad when they find out a standardized connector isn't the same thing as a standardized cable.
I like the Humble Bundle. I've bought rather a lot of games, comics, and books there.
Usually the comics and books have been DRM-free, but recently they've had a couple of bundles, including a Discworld bundle and a TMNT bundle (still available as of this post), that, instead of being straight DRM-free file downloads, required that buyers redeem DRM-encumbered files from Kobo.
Fortunately, it's not difficult to strip DRM from Kobo downloads, so that you can read your books on whatever device and in whatever app you choose. Here's how:
Download DeDRM tools (make sure you get it from the noDRM repository, not the original apprenticeharper one; the latter is no longer maintained).
Extract the zip file.
In Calibre, go to Preferences → Advanced → Plugins. Click "Load plugin from file", browse to the directory you just unzipped into, and install both _plugin.zip files. Restart Calibre after both are installed.
Install Kobo Desktop (direct link to kobosetup.exe). Run it, log into your Kobo account, and download the books you want. Once they're finished downloading, quit out of the Kobo app.
In Calibre, click the "Obok DeDRM" link in the top bar. From there it's pretty self-explanatory; whatever books you select will be added to your Calibre library and you can find the epub files in your file browser.
That's it for stripping the DRM, but there's one more thing I noticed: it turns out that my comics reader app of choice, Perfect Viewer, doesn't really work very well with epub files; for some reason it doesn't support the same features for epub as it does for cbz/cbr/pdf files (eg automatically showing two pages when rotated). Fortunately, there's a dead-simple workaround: change the file extension from .epub to .cbz. (A CBZ is just a zip file of images; an EPUB is basically a zipped website. Change the extension from EPUB to CBZ and PerfectViewer just ignores the HTML files and looks for the images.) YMMV depending on your reader of choice; some will show side-by-side pages without issue (like Calibre's built-in reader) and the file extension trick may not work in others (since the images aren't at the root of the zip file; in that case you may need to extract the EPUB and then re-zip just the images into a CBZ file).
If you're a longtime reader of Satellite News (mst3kinfo.com) like me, you know that it's got a pretty good comments section, except for two things:
A particularly obnoxious and persistent troll by the name of EricJ who insists on pissing in everyone's cornflakes; and
A bunch of other posters with poor self-control who insist on responding to him.
And so, in the tradition of my Hide Techdirt Comments script, I've written a userscript that will block EricJ and replies that quote him. Works with Greasemonkey, Tampermonkey, and presumably any other similar userscript plugins that may be out there.
If there's anybody else who bothers you, you can add other usernames to the blacklistedUsers array, too.
And ordinarily, I wouldn't even name the troll I was talking about, because the entire point here is that you shouldn't give trolls the attention they crave -- but I figure you know, this post might prove useful to other Satellite News commenters, so I should probably put his name in it so that maybe somebody will find it while searching for a way to block all comments from, and replies to, The Original EricJ on mst3kinfo.com.
Enjoy.
// ==UserScript==
// @name Hide Satellite News Comments
// @namespace http://corporate-sellout.com
// @description Hide comments on mst3kinfo.com, based on user
// @include http://www.mst3kinfo.com/?p=*
// @require http://www.mst3kinfo.com/wp-includes/js/jquery/jquery.js
// ==/UserScript==
// List of users whose comments you want to hide --
// you can add more names to this list, but let's be honest, you want to block EricJ.
const blacklistedUsers = [
'The Original EricJ'
];
const $ = jQuery;
// Comment class
// Constructor
function Comment(node) {
this.node = node;
this.nameBlock = $('.comment-author > .fn > a', this.node);
this.name = this.nameBlock.text();
this.quotedUserBlock = $('a[href^="#comment"]', this.node);
this.quotedUser = this.quotedUserBlock.length === 1
? this.quotedUserBlock.text()
: '';
}
// Functions
Comment.prototype = {
constructor: Comment,
check: function() {
if(
blacklistedUsers.includes(this.name)
|| (this.quotedUser !== '' && blacklistedUsers.includes(this.quotedUser))
) {
this.node.remove();
return true;
}
return false;
}
};
$('.comment').each(function() {
const cmt = new Comment($(this));
cmt.check();
});
License
I'm not a lawyer, but my opinion as a programmer is that this script is too short, simple, and obvious to be copyrightable. As such, I claim no copyright, and offer no license, because none is needed. Use it however you want, with the standard disclaimer that it comes with absolutely no warranty.
I've spent the past week and a half softmodding my Wii U and ripping my library to it.
There are a few reasons for this -- the primary one being that the copy of Breath of the Wild that I bought used worked for about the first ten hours of the game and then quit reading.
Another reason is, it'll be nice to be able to put all my discs in a box somewhere and get some shelf space back.
The guide at wiiu.guide is a great walkthrough for softmodding your Wii U. But there are a few details I had to figure out myself, and I'm going to share them here.
First of all, here's the hardware I used:
A 1TB Western Digital Elements USB3 hard drive. This is excessive; I have 11 games installed on it and they only take up about 90 GB of space. However, I happened to have it lying around unused (I'd bought it for my grandma as a backup drive and discovered, when I went over to her house, that she already had a backup drive), so that's what I went with.
It's probably a good idea to repartition and reformat the SD card before you get started. I found that mine had a few MB of unpartitioned space at the beginning, and I got an error with the NAND backup program saying it wasn't a FAT32 disk.
Also, make sure the FS type is C. That's FAT32. I used mkdosfs and wound up with 7 (ExFAT).
Something to note about the hard drive: I didn't need the Y-connector that wiiu.guide recommends, but I did need to plug it into one of the USB ports on the back of the console (I went with the top one). When I plugged it into one of the front USB ports, it would frequently hang on long file copies. When I plugged it into the top back port, it worked fine.
Copy all your save data before you rip any games. By this I mean, as soon as you format the hard drive to Wii U format, go into Wii Settings and Data Management, and copy all your save data. (It's safer to copy it than to move it; if you want to delete it from your NAND, wait until you've made sure it works first. A NAND backup and SaveMii backups are probably a good idea too, just to make sure you don't lose anything.)
This is totally counterintuitive, but here's how it works: save data on the NAND works for disc games (and, presumably, games stored on the NAND, though I haven't verified this), but games installed on the hard drive will completely ignore it. If you've got Breath of the Wild installed on your hard drive, and a saved game and a few gigs of updates installed on the NAND, then when you fire up Breath of the Wild it will behave as if it's being run for the first time. It will try to download updates, and start you out at the beginning. If you want a game that's installed on your hard drive to see your updates and your saves, then they have to be stored on the hard drive too, not the NAND.
And, even more counterintuitively, you have to copy the saves first. If you install the game on your hard drive and then copy the save data over, the save data will overwrite the game on the hard drive and you'll have to reinstall it. But if you copy the save data and then install the game, the game won't overwrite the save; the save will still be there and the first time you run the game off the hard drive, all your save data, updates, and DLC will be there, ready to go.
Hope that helps somebody. It would have saved me a lot of extra hours if I'd known that stuff before I started instead of having to figure it out for myself.
Updated 2022-02-28: Updated script for the new Techdirt comment engine.
Updated 2021-04-30: Fixed a bug that was preventing some replies from being hidden.
Updated 2019-09-11: Minor update because the site layout has changed slightly and the old version was no longer working.
Updated 2019-04-11: General cleanup; change to OOP.
Remove some techniques that are no longer needed since recent Techdirt update; add handling for some new types of predictable troll behavior.
Better blocking of flagged users who aren't logged in.
Updated 2018-08-19: Hide comments that have already been hidden by user flagging (this is mostly useful if the hideReplies boolean is set true).
Updated 2018-08-15: Added hideLoggedOut. If set true, then the script will hide any user who isn't logged in, unless their name is in the whitelist array.
Added hideReplies. If set true, then when the script hides a comment it will also hide all the replies to the comment.
If you set both hideLoggedOut and hideReplies to true, then the Techdirt comments section gets much quieter.
Updated 2018-08-09: Some doofus has been impersonating me. Script will now automatically flag and hide posts by fake Thad.
In addition to hiding posts if their subject line is too long, the script will now also hide posts if the username is too long. Additionally, the script can automatically flag posts if the subject or username exceeds a specified length.
This thing's gotten complicated enough that I think it's probably subject to copyright now. I've added a license. I chose a 3-Clause BSD License.
Updated 2018-06-20: Ignore mixed-case and non-alpha characters.
Updated 2018-03-06: Fixed case where usernames inside links were not being blocked.
Updated 2018-03-04: Added function to hide long subject lines, because some trolls like to write manifesto-length gibberish in the Subject: line.
There is now a maxSubjectLength variable (default value: 50). Any subject line exceeding that length will be hidden. If you reply to a post with a subject line exceeding that length, your reply's subject line will default to "Re: tl;dr".
Updated 2017-07-12: Added @include.
In my previous post, I mentioned that I spend too much of my life responding to trolls on Techdirt.
With that realization, I whipped up a quick Greasemonkey/Tampermonkey script to block all posts from specified usernames.
// ==UserScript==
// @name Hide Techdirt Comments
// @namespace https://corporate-sellout.com
// @description Hide comments on Techdirt, based on user and other criteria.
// @include https://www.techdirt.com/*
// @require https://c0.wp.com/c/5.9.1/wp-includes/js/jquery/jquery.min.js
// ==/UserScript==
const $ = jQuery;
// Boolean settings:
// if true, hide all posts from users who aren't logged in
const hideLoggedOut = true,
// if true, hide all replies to hidden posts
hideReplies = true;
// List of users whose comments you want to hide -- collect 'em all!
const blacklistedUsers = [
'btr1701',
'Koby',
'Richard Bennett'
],
// If an anonymous post begins with one of these strings, hide it
blacklistedStrings = [
'out_of_the_blue',
'Nothing to hide, nothing to fear'
],
// List of users whose comments you don't want to hide
whitelistedUsers = [
'Chip',
'Thad'
];
// global variable for storing gravatars of non-logged-in posters who have been blocked
let blockedGravatars = [],
// global variable for storing comments that aren't hidden
comments = [];
// check all non-hidden comments for a blocked gravatar
// (check each time a gravatar is blocked)
function checkCommentsForBlockedGravatar(blockedGravatar) {
for(let i=0; i<comments.length; i++) {
if(comments[i].gravatar === blockedGravatar) {
comments[i].gravatarBlocked = true;
comments[i].removeComment();
}
}
}
// Comment class
// Constructor
function Comment(node) {
this.container = node;
this.body = $('> .comment-body', this.container);
this.nameBlock = $('.comment-author', this.body);
this.name = $('> .fn', this.nameBlock).text();
this.linkNode = $('> .url', this.nameBlock);
this.loggedIn = this.linkNode.length > 0
&& this.linkNode.attr('href').startsWith('https://www.techdirt.com/user/');
this.gravatar = $('> img', this.nameBlock).attr('src');
this.gravatarBlocked = false;
this.flagBtn = $('.report-button', this.body);
this.alreadyHidden = this.container.hasClass('flagged');
this.alreadyFlagged = this.flagBtn.hasClass('has-rating');
this.postContent = $('.comment-content', this.body).text().trim();
// If I click on the "Flag" button, remove the comment
var that = this;
that.flagBtn.one('click', function() {
that.removeComment();
});
}
// Functions
Comment.prototype = {
constructor: Comment,
checkForBlockedGravatar: function() {
if(this.loggedIn) {
return false;
} else if(this.gravatarBlocked !== true) {
// only need to find gravatar in blockedGravatars array once;
// once this.gravatarBlocked is set true, then it will always be true.
this.gravatarBlocked = blockedGravatars.includes(this.gravatar);
}
return this.gravatarBlocked;
},
blockGravatar: function() {
this.gravatarBlocked = true;
blockedGravatars.push(this.gravatar);
checkCommentsForBlockedGravatar(this.gravatar);
},
removeComment: function() {
if(hideReplies === true) {
this.container.remove();
} else {
// replace comment with 'removed'
// -- because replies will still be visible, this is necessary
// so you can tell there's a missing post that they're replying to.
this.body.text('removed');
}
if(!this.loggedIn && !this.gravatarBlocked) {
this.blockGravatar();
}
},
badStart: function() {
for(let i=0; i<blacklistedStrings.length; i++) {
if(this.postContent.startsWith(blacklistedStrings[i])) {
return true;
}
}
return false;
},
check: function() {
if(
this.alreadyHidden
|| this.alreadyFlagged
|| this.checkForBlockedGravatar() === true
|| blacklistedUsers.includes(this.name)
|| (this.loggedIn === false && hideLoggedOut === true && !whitelistedUsers.includes(this.name))
|| (this.name === 'Anonymous Coward' && this.badStart())
) {
this.removeComment();
return true;
}
return false;
}
};
$('div.comment').each(function() {
// skip comment if it's already been removed
if(document.contains($(this)[0])) {
const cmt = new Comment($(this));
if(cmt.check() === false) {
comments.push(cmt);
}
}
});
License
Copyright 2017-2021 Thaddeus R R Boyd
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
Neither the name of the copyright holder nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
Further Thoughts
(Note: The script was much smaller when I originally wrote this part of the post.)
This is a blunt instrument; it took about five minutes to write. It lacks subtlety and nuance.
Blocking all anonymous posters on Techdirt is not an ideal solution; most anons aren't trolls. (Most trolls, however, are anons.) I apologize to all the innocent anons blocked by this script.
I could make the script more precise. Techdirt's trolls are creatures of habit with certain noticeable verbal tics (more on that below); if I had a good parser, I think I could whip up a scoring system that could recognize troll posts with a high degree of accuracy.
The question is, how much time do I want to spend on that?
On the one hand, "five minutes in a text editor" is the appropriate amount of time for dealing with forum trolls. Anything else seems like more effort and attention than they deserve.
On the other hand, it's a potentially interesting project, I've always wanted to spend some time studying natural language processing, and any programming project is time well-spent if it teaches you a new skill.
So I haven't decided yet. Here's the script as it stands, in its initial, blunt-instrument-that-took-five-minutes form. If I update the script, I'll update this post.
Chip Tips
Lastly, as I can no longer see anonymous posts, this means I will likely have to give up my beloved sockpuppet, Chip, the man who hates all government regulations and loves to eat leaded paint chips. To anyone and everyone else who wants to keep the spirit of Chip alive, you have my blessing to post under his name.
A few tips on how to write as Chip:
Never use the backspace key.
Remember to add random Capital Letters and "quotation marks" to your posts, in Places where they "don't" make Sense!
Most sentences should end with Exclamation Points!
I told you So!
I have "lots" of Solutions! So many I can't Name a single "one"!
Sycophantic Idiots!
Every Nation eats the Paint chips it Deserves!
Boy, my regular readers are going to have no fucking idea what I'm talking about in this post.
Come back tomorrow; I plan on having a post about online privacy that should be a little less niche.
You've probably heard by now that the US Congress just repealed Obama-era regulations preventing Internet service providers from selling their users' browsing data to advertisers. I'll probably talk more about that in future posts. For now, I'm going to focus on a specific set of steps I've taken to prevent my ISP (Cox) from seeing what sites I visit.
I use a VPN called Private Internet Access, and a hardware firewall running pfSense. If that sentence looked like gibberish to you, then the rest of this post is probably not going to help you. I plan on writing a post in the future that explains some more basic steps that people who aren't IT professionals can take to protect their privacy, but this is not that kind of post.
So, for those of you who are IT professionals (or at least comfortable building your own router), it probably won't surprise you that streaming sites like Netflix and Hulu block VPNs.
One solution to this is to use a VPN that gives you a dedicated IP (I hear good things about NordVPN but I haven't used it myself); Netflix and Hulu are less likely to see that you're using a VPN if they don't see a bunch of connections coming from the same IP address. But there are problems with this approach:
It costs more.
You're giving up a good big chunk of the anonymity that you're (presumably) using a VPN for in the first place; your ISP won't be able to monitor what sites you're visiting, but websites are going to have an easier time tracking you if nobody else outside your household is using your IP.
There's still no guarantee that Netflix and Hulu won't figure out that you're on a VPN and block your IP, because VPNs assign IP addresses in blocks.
So I opted, instead, to set up some firewall rules to allow Netflix and Hulu to bypass the VPN.
The downside to this approach is obvious: Cox can see me connecting to Netflix and Hulu, and also Amazon (because Netflix uses AWS). However, this information is probably of limited value to Cox; yes, they know that I use three extremely popular websites, when I connect to them, and how much data I upload and download, but that's it; Netflix, Hulu, and Amazon all force HTTPS, so while Cox can see the IPs, it can't see the specific pages I'm going to, what videos I'm watching, etc. In my estimation, letting Cox see that I'm connecting to those sites is an acceptable tradeoff for not letting Cox see any other sites I'm connecting to.
There are a number of guides on how to get this set up, but here are the three that helped me the most:
OpenVPN Step-by-Step Setup for pfsense -- This is the first step; it'll help you route all your traffic through Private Internet Access. (Other VPNs -- at least, ones that use OpenVPN -- are probably pretty similar.)
Hulu Traffic -- Setting up Hulu to bypass the VPN is an easy and straightforward process; you just need to add an alias for a set of FQDNs and then create a rule routing connections to that alias to WAN instead of OpenVPN.
Netflix to WAN not OPT1 -- Netflix is trickier than Hulu, partly because (as mentioned above) it uses AWS and partly because the list of IPs associated with AWS and Netflix is large and subject to change. So in this case, instead of just a list of FQDNs, you'll want to set up a couple of rules in pfBlockerNG to automatically download, and periodically update, lists of those IPs.
That's it. Keep in mind that VPN isn't a silver bullet solution, and there are still other steps you'll want to take to protect your privacy. I'll plan on covering some of them in future posts.
This one is probably obvious, but just in case it isn't: I started with a short story because when you want to learn a new skill, you want to start small. I didn't want to write something novel-length and then run into a bunch of problems.
A short story's the perfect length to start with. Old Tom and the Old Tome clocks in around 3,000 words, split up into 4 separate sections (cover, copyright, story, About the Author). It has a great structure for learning the ropes.
Of course, you don't have to go the fiction route. In fact, it occurs to me that this blog post would actually convert quite nicely into a short eBook. Hm, food for thought.
Scrivener
I checked out Scrivener because Charles Stross swears by it. It's basically an IDE for writing books; it's quite simply the most advanced and mature piece of software there is for the purpose.
There's a Linux version, but it's abandonware. For a GNU/Linux user such as myself, this is something of a double-edged sword: on the plus side, I get Scrivener for free, where Mac and Windows users have to pay $40 for it; on the minus side, if a system upgrade ever causes it to stop working, I'm SOL. If Scrivener stops working on my system, there's not going to be a fix, I'll be locked into a platform I can no longer use. I could try and see if the Windows version will run under WINE, but there's no guarantee of that.
The good news is that Scrivener saves its files in standard formats, so if it ever stops working I'll still be able to access my content in other programs. The bad news is that it saves its individual files with names like 3.rtf and 3_synopsis.txt.
So Scrivener's pretty great, and I'll probably stick with it for a little while even though there are no more updates on the horizon for my OS -- but there's a definite downside to using the Linux version. (And if they decided the Linux version wasn't going to bring in enough profit to justify maintaining it, what happens if they decide the same thing for the Windows version someday, maybe leave it as a Mac-only product?)
Getting Started
Scrivener's got a great tutorial to run through its functionality; start there.
When you're done with the tutorial and ready to get to work on your book, I recommend using the Novel template, even if you're not writing a novel, because it automatically includes Front Matter and Back Matter sections; the Short Story template does not.
Scrivener's got your standard MS-word-style tools for formatting your work. I didn't use them. Since I was targeting a digital-only release and no print version, I wrote my story in Markdown, which converts trivially to HTML but isn't as verbose as HTML.
Output Formats
Since I went the Markdown route, I found that the best option for output at compile time was Plain Text (.txt). The most vexing thing I found about the output was the limited options under the "Text Separator" option -- the thing that goes between different sections. What I wanted was a linebreak, followed by ***, followed by another linebreak. Scrivener doesn't have any option for that -- your options are Single Return, Empty Line, Page Break, and Custom. Under Custom you can put ***, but there doesn't seem to be any way to put a linebreak on either side of it. So I found the best option was to just do that, and then manually edit the text file it put out and add a linebreak on either side of each one.
If you plan on making an EPUB file, you'll probably want to keep all the "smart quotes" and other symbols that Scrivener adds to your text file. However, if you want to distribute the Markdown file in plain text and want it to be readable in Chrome, you'll need to remove all the pretty-print characters, because Chrome won't render them correctly in a plain-text file (though it'll do it just fine in a properly-formatted HTML file). You'll also want to use the .txt extension rather than .md or .markdown if you want the file to display in Firefox (instead of prompting a download).
You've got different options for converting from Markdown to HTML. Pandoc is a versatile command-line tool for converting between all sorts of different formats, but I don't like the way it converts from Markdown to HTML; not enough linebreaks or tabs for my tastes. There are probably command-line flags to customize those output settings, but I didn't find them when I glanced through the man page.
I thought Scrivener's Multimarkdown to Web Page (.html) compile option worked pretty well, although the version I used (1.9 for Linux) has a bug that none of the checkboxes to remove fancy characters work correctly: you're getting smartquotes whether you want them or not. You also don't want to use *** as your section separator, because Scrivener reads it as an italicized asterisk (an asterisk in-between two other asterisks, get it?) instead of an HR. Similarly, it reads --- as an indicator that the previous line of text is an h2.
So your best bet for a section break is something like
</p><hr/><p>
or
<div class="break">*</div>
(Actually, you don't want to use HR's at all in an EPUB, for reasons I'll get to later, but if you want to distribute an HTML version of your book, it's fine to use them in that version.)
Sigil
Sigil is an excellent, very straightforward tool for editing the EPUB format. I recommend you grab the Sigil User Guide, go through the Tutorial section, and do what it tells you -- even the stuff that generates seemingly ugly code. For example, if you use Sigil's Add Cover tool, you wind up with code that looks like this:
If you're like me, looking at that makes you wince. And your instinct will be to replace it with something simple, like this:
<img src="../Images/cover.jpg" alt="Cover" />
But don't do that. Removing the <svg> tag, or even removing those ugly-ass inline styling attributes, will prevent the cover from displaying correctly as a thumbnail in readers.
(If there is a way to clean up that ugly <svg> tag and still have the thumbnail display correctly, please let me know; I'd love to hear it.)
Now, Sigil is for the EPUB2 format. It doesn't support any of the newfangled fancy features of EPUB3, and neither do most readers at this point. You're going to want to keep your styles simple. In fact, here's the entire CSS file from Old Tom and the Old Tome:
Oh, and that last class, .break? That's there because some readers ignore <hr/> tags. FBReader on Android, for example, will not display an HR. No matter how I tried formatting it, it wouldn't render. Not as a thin line, not even as a margin. If you use an <hr/> tag in your EPUB file, FBReader will act as if it isn't there.
So I wound up cribbing a style I saw in Tor's EPUB version of The Bloodline Feud by Charles Stross:
<div class="break">*</div>
where, as noted in the above CSS, the .break class centers the text and puts a 1em margin above and below it.
(Some readers won't respect even that sort of simple styling, either; Okular parses the margin above and below the * but ignores the text-align: center style. Keep this in mind when you're building an EPUB file: keep the styles simple, and remember that some readers will straight-up ignore them anyway.)
(Also: this should go without saying, but while it's okay to look through other eBooks for formatting suggestions and lifting a few lines' worth of obvious styling is no problem, you don't want to go and do anything foolish like grab an entire CSS file, unless it's from a source that explicitly allows it. Even then, it might not be a good idea; formatting that works in somebody else's book may not be a good idea in yours.)
Testing
Once my EPUB was done, I tested it in a number of different readers for a number of different platforms at a number of different resolutions. There are a lot of e-readers out there, and their standards compliance is inconsistent -- much moreso than the browser market, where there are essentially only three families of rendering engines.
If you're used to using an exhaustive, precise set of CSS resets for cross-browser consistency, you probably expect to use something similar for e-readers. Put that thought out of your head; you're not going to find them. The best you're going to get are a few loose guidelines.
Consistency across different e-readers just isn't attainable in the way that it is across different web browsers. Don't make that a goal, and don't expect it to happen. You're not looking for your eBook to display perfectly in every reader; you're just looking for it to be good enough in a few of the most-used readers.
For example, I found that the margins the Nook reader put around my story were fine on a tablet, but I thought they were too much on a phone. If I'd wanted, I could have futzed around with media queries and seen if that was possible to fix -- but I decided no, it was Good Enough; it wasn't worth the effort of trying to fix it just for that one use-case.
If you already know HTML, here's what I can tell you about the Smashwords Style Guide: read the FAQ at the beginning, then skip to Step 21: Front Matter. Because it turns out that Steps 1-20 are about how to try and make Microsoft Word output clean HTML and CSS. If you already know how to write HTML and CSS yourself, there is of course absolutely no fucking reason why you would ever want to use Word to write your HTML and CSS for you.
It's probably a good idea to read the rest of the guide from Step 21 through the end, but most of it's pretty simple stuff. To tell the truth, there are exactly two modifications I made to the EPUB for the Smashwords edition: I added the phrase "Smashwords edition" to the copyright page, and I put ### at the end of the story (before the back matter). That's it.
For all the time the guide spends telling you how easy it is to fuck up and submit a file that will fail validation, I experienced none of that. My EPUB validated immediately, and it was approved for Smashwords Premium the next day (though Smashwords says it usually takes 1-2 weeks; the quick turnaround may have been a function of how short my short story is).
Description
Most of the forms you fill out on the Smashwords Publish page are well-documented and/or self-explanatory. The Long Description and Short Description fields are exceptions; it's probably not entirely clear, at a glance, where your listing will show the short description and where it will show the short one. So here's how they work:
On Smashwords, your book's listing shows the short description, followed by a link that says "More". When you click "More", the long description appears underneath the short description.
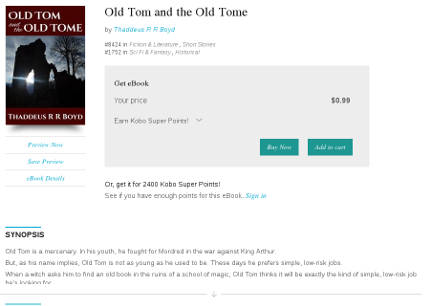
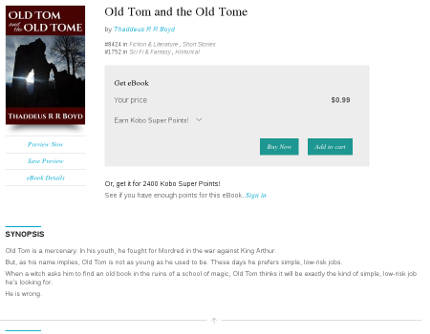
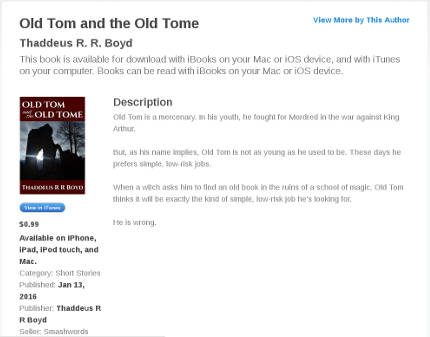
Smashwords
Kobo and iBooks don't appear to use the short description at all. Your book's listing will show the first few lines of your long description, followed by an arrow (on Kobo) or a "More..." link (on iBooks), which you can click to expand to show the entire description.
Kobo
iBooks
Aside: Why the fuck does it do this?
Look at all that whitespace. What's the point of hiding the text?
Inktera shows the long description, followed by an HR, followed by the short description.
Lastly, Blio doesn't show either description of my book. Clearly this is a problem and I should probably talk to tech support about it.
As you might expect, the various different ways the different sites use the two descriptions create a bit of a conundrum: how can you write a short description that is the primary description on one site and a long description that is the primary description on four other sites, and write the two descriptions so that they don't look pointless and redundant when you put them side-by-side?
I haven't come up with a good solution for this in the case of Old Tom yet.
Amazon
It turns out the Amazon conversion is really easy. I just set up an account at kdp.amazon.com, filled out the forms, uploaded the cover and the EPUB file, and Amazon's automatic conversion software switched it over to Kindle format with no trouble at all. Amazon's even got a really nice online reader that lets you check how your file will look in the Kindle Reader on various devices (Kindle Fire HD, iPhone, iPad, Android phone, Android tablet, etc.).
I only hit one speed bump when I submitted to Amazon: after a few hours, I got an E-Mail back saying that the book was freely available online (because of course it is; I've posted it in multiple places, including this site). Amazon required me to go back through and reaffirm that I am the copyright holder of the book -- which meant just going through the exact same forms I'd already filled out and clicking the Submit button again. It was a little bit annoying, but not time-consuming and mostly painless, and the book appeared for download on Amazon shortly after.
And that's it.
The hardest part of self-publishing an eBook was finding the time, figuring out what resources to use, and learning the EPUB format. And now that I know what resources to use and understand the EPUB format, it doesn't take nearly as much time. For my next book, I'll be able to spend a lot more time writing and a lot less time formatting. Hopefully this blog post has helped you so that you can do the same.
So the other day I decided it was past time to reset all my passwords.
I'm pretty good about password hygiene. I've been using a password locker for years, with a unique, randomly-generated* password for every account I use. But I'll admit that, like most of us, I don't do as good a job of password rotation as I might. That's probably because I've managed to amass over 150 different accounts across different sites, and resetting 150 different passwords is a giant pain in the ass.
(I'm thinking that, from here on in, I should pick a subset of passwords to reset every month, so I never wind up having to reset all 150 at once again. It would also help me to clear out the cruft and not keep logins for sites that no longer exist, or which I'm never going to use again, or where I can't even find the damn login page anymore.)
There was one more reason I decided now was a good time to do a mass update: I've got two E-Mail addresses that have turned into spam holes. As I've mentioned previously, I'm currently looking for work and getting inundated with job spam; unfortunately I went and put my primary E-Mail address at the top of my resume, which in hindsight was a mistake. Never post your personal E-Mail in any public place; always use a throwaway.
Which I do, most of the time -- and that's created a second problem: I've been signing up for websites with the same E-Mail address for 15 years, and also used to use it in my whois information. (I've since switched to dedicated E-Mail addresses that I use only for domain registration.) So now, that E-Mail has turned into a huge spam hole; it's currently got over 500 messages in its Junk folder, and that's with a filter that deletes anything that's been in there longer than a week. My spam filters are well-trained, but unfortunately they only run on the client side, not the server side, so any time Thunderbird isn't running on my desktop, my spam doesn't get filtered. (If I'm out of the house, I can tell if the network's gone down, because I start getting a bunch of spam in my inbox on my phone.)
So now I've gone and created two new E-Mail addresses: one that's just for E-Mails about jobs, and another as my new all-purpose signing-up-for-things address.
My hope is that the companies hammering my primary E-Mail address with job notifications will eventually switch to the new, jobs-only E-Mail address, and I'll get my personal E-Mail address back to normal. And that I can quit using the Spam Hole address entirely and switch all my accounts over to the new address. Which hopefully shouldn't get as spam-filled as the old one since I haven't published it in a publicly-accessible place like whois.
Anyway, some things to take into account with E-Mail and passwords:
Don't use your personal E-Mail address for anything but personal communication. Don't give it to anyone you don't know.
Keep at least one secondary E-Mail address that you can abandon if it gets compromised or filled up with spam. It's not necessarily a bad idea to have several -- in my case, I've got one for accounts at various sites, several that I use as contacts for web domains, and one that's just for communication about jobs.
Use a password locker. 1Password, Keepass, and Lastpass are all pretty highly-regarded, but they're just three of the many available options.
Remember all the different devices you'll be using these passwords on.
I'm using a Linux desktop, an OSX desktop, a Windows desktop, and an Android phone; that means I need to pick a password locker that will run on all those different OS's.
And have some way of keeping the data synced across them.
And don't forget that, even with a password locker, chances are that at some point you'll end up having to type some of these passwords manually, on a screen keyboard. Adding brackets and carets and other symbols to your password will make it more secure, but you're going to want to weigh that against the hassle of having to dive three levels deep into your screen keyboard just to type those symbols. It may be worth it if it's the password for, say, your bank account, but it's definitely not worth it for your Gmail login.
Of course, you need a master password to access all those other passwords, and you should choose a good one. There's no point in picking a bunch of unique, strong passwords if you protect them with a shitty unsecure password. There are ways to come up with a password that's secure but easy to remember:
The "correct horse battery staple" method of creating a passphrase of four random words is a good one, but there are caveats:
You have to make sure they're actually random words, words that don't have anything to do with each other. Edward Snowden's example, "MargaretThatcheris110%SEXY.", is not actually very secure; it follows correct English sentence structure, "MargaretThatcher" and "110%" are each effectively one word since they're commonly-used phrases, the word "SEXY" is common as fuck in passwords, and mixed case and punctuation don't really make your password significantly more secure if, for example, you capitalize the beginnings of words or entire words and end sentences with periods, question marks, or exclamation points. Basically, if you pick the words in your passphrase yourself, they're not random enough; use a computer to pick the words for you.
And this method unfortunately doesn't work very well on a screen keyboard. Unless you know of a screen keyboard that autocompletes words inside a password prompt but won't remember those words or their sequence. I think this would be a very good idea for screen keyboards to implement, but I don't know of any that do it.
There are programs and sites that generate pronounceable passwords -- something like "ahx2Boh8" or "ireeQuaico". Sequences of letters (and possibly numbers) that are gibberish but can be pronounced, which makes them easy to remember -- a little less secure than a password that doesn't follow such a rule, but a lot more secure than a dictionary word. But read reviews before you use one of these services -- you want to make sure that the passwords it generates are sufficiently random to be secure, and that it's reputable and can be trusted not to snoop on you and send that master password off to some third party. It's best to pick one that generates multiple passwords at once; if you pick one from a list it's harder for a third party to know which one you chose.
Of course, any password is memorable if you type it enough times.
And no password is going to protect you from a targeted attack by a sufficiently dedicated and resourceful attacker -- if somebody's after something you've got, he can probably find somebody in tech support for your ISP, or your registrar, or your hosting provider, or your phone company, or some company you've bought something from, somewhere, who can be tricked into giving him access to your account. Or maybe he'll exploit a zero-day vulnerability. Or maybe one of the sites you've got an account with will be compromised and they'll get everybody's account information. Password security isn't about protecting yourself against a targeted attack. It's about making yourself a bigger hassle to go after than the guy sitting next to you, like the old joke about "I don't have to outrun the tiger, I just have to outrun you." And it's about minimizing the amount of damage somebody can do if he does compromise one of your accounts.
And speaking of social engineering, security questions are deliberate vulnerabilities, and they are bullshit. Never answer a security question truthfully. If security questions are optional, do not fill them out. If they are not optional and a site forces you to add a security question, your best bet is to generate a pseudorandom answer (remember you may have to read it over the phone, so a pronounceable password or "correct horse battery staple"-style phrase would be a good idea here, though you could always just use letters and numbers too -- knowing the phonetic alphabet helps) and store it in your password locker alongside your username and password.
You know what else is stupid? Password strength indicators. I once used one (it was Plesk's) that rejected K"Nb\:uO`) as weak but accepted P@55w0rd as strong. You can generally ignore password strength indicators, unless they reject your password outright and make you come up with a new one.
* For the purposes of this discussion, I will be using the words "random" and "pseudorandom" interchangeably, because the difference between the two things is beyond the scope of this post.
Update 2015-10-12: My new advice for getting Sprint data to work on a Nexus 5 phone running CyanogenMod 12 is "Don't bother." I never did get it working right, and had to reboot at least once a day to get it working. I've since reverted back to KitKat. Original post follows, but if you want my advice it's "Stick with CM11."
First, let's get one thing out of the way: if you're using a custom Android ROM on your phone (or any device that can receive text messages), you're going to want to make sure it's up-to-date. There's a vulnerability in an Android component called Stagefright that is potentially devastating; it allows an attacker to gain control by doing nothing more than send a text message, and there are now attacks in the wild.
If you've got the stock firmware on your phone, and your phone is relatively recent, you should get the patch to fix this vulnerability automatically. (If, for example, your phone is running Lollipop, either because it came with it or automatically updated to it, you're probably good.)
But if you're running a custom ROM and don't have automatic updates enabled, you're going to want to check on whether you're running a current version that includes the Stagefright fix.
I'm a CyanogenMod user. If you're using the latest version of CyanogenMod 11.0, 12.0, or 12.1, then you've got the Stagefright fix.
I recently took the opportunity to upgrade my phone to the latest 11.x series to get the fix. And I figured while I was at it, why not upgrade to 12.1 and see if it's any good?
So I installed CyanogenMod 12.1, and everything looked like it was working fine at first -- when I was using it in my own house, on my wifi network. It wasn't until a day or two later that I realized my Sprint data connection wasn't working.
It took rather more searching than it should have, but it turns out there's an easy solution (albeit an annoying one if you've already got your phone set up the way you want it, because it involves wiping it to factory again).
mjs2011 at XDA Developers links to a sprint.zip file assembled by somebody named Motcher41, and gives these instructions for use:
The fix should be flashed during initial installation, so:
Flash ROM
Gapps
SU (if necessary)
Sprint APN Fix zip
I can confirm that you don't need to worry about setting up root before sprint.zip; it's fine if you do it afterward (my recovery, for example, sets up su right before reboot). However, I can confirm that you need to install sprint.zip after Gapps and before your first boot; if you install it before Gapps or after your first boot then it won't work.
Update 2015-09-30: After a few days my data connection quit working again. I rebooted to recovery, reinstalled sprint.zip, and it started working again. So never mind about not working if you install it after you've already booted the ROM; it will still work just as well. Unfortunately, "just as well" appears to mean "just for a few days"; I'm not sure what happened that changed my settings to make it stop working, but if I figure it out I'll update this post again.
You may notice that the linked thread is old (it's from November 2013) and was written in reference to pre-11.0 versions of CyanogenMod. However, I can confirm that it applies to the 12.x series too. This issue appears to be a regression; CM fixed it in version 11 but then broke it again in version 12.
So if you're a Sprint customer and you just installed CyanogenMod 12 on your phone and then discovered Sprint data was no longer working, this is what you're gonna wanna do to fix it.
It's probably not surprising that rebuilding my website has gotten me thinking about web development.
The first six years I ran this site, I did it all by hand -- my own HTML, my own CSS, no scripting languages. I thought that CMS software was for pussies.
But ultimately, plain old HTML just doesn't scale. I conceded that when I started using b2evolution for my blog back in '06, and it's truer now than it was then.
You can poke around some of the old sections of the site a bit, the ones that haven't been updated significantly since the turn of the century -- KateStory's a good one, or the Features page (though I'd like to get at least the Features page up to date sooner than later, and maybe the KateStory one too, so maybe there'll be people reading this post well after those pages shed their 1990's style) -- and they get the job done. Breadcrumb navigation at the bottom of every section, leading you back to either the parent page or the main index.
But Jesus, you can only manually copy and paste "Back to Features / Back to Index" so many times.
And maintaining a years-long blog archive without a CMS to automate it for you? It gets old.
So, you want some automation? You're going to need a scripting language. That usually means PHP for server-side, and JavaScript for client-side.
I got to thinking the other day -- man, it's weird that you need extra toolsets to perform such common tasks as, say, reusing a navigation bar. It's weird that there's not some way just to write up a navigation bar and then write code, in HTML, no scripting required, to embed that common HTML block on the current page.
I thought this was a pretty smart observation.
For about three seconds.
At which point I realized I had just described fucking frames.
Course, the biggest problem with frames is that they weren't exactly what I'm describing. I'm talking about just an HTML snippet in some secondary file that you call from a primary file -- like an include in PHP.
That's not what frames were. Frames were complete fucking HTML pages -- <html>, <head>, <body> (or, more likely, <HTML>, <HEAD>, <BODY>, because in the old days we wrote HTML tags in all-caps) -- which is, most times, downright stupid and wasteful, and was much moreso in the days of 14.4 dialup. Even worse than the load time was the logistics -- if you used frames to build a website with a header, a footer, and a sidebar, you'd have a total of five separate web pages -- a content area, the three other sections, and some kind of main page that all of them were embedded into. This was a fucking nightmare for linking, both for the developer (who had to remember to set the target attribute on every single link, lest the page load in the navigation bar instead of the content area) and the end user (because the URL in the location bar would be the container page that called all the other pages, not the content page the user was currently looking at).
In a way, it's kinda weird that nobody's gone back to that well and tried to do it again, but do it right this time. Update the HTML spec to allow an HTML file to call a reusable snippet of HTML from another file, one that isn't a complete page.
Given all the concessions HTML5 has made to the modern Web, it's surprising that hasn't happened, even given how slowly it takes for a spec to be approved. We've got a <nav> tag, which is nice and all, but who the hell uses a <nav> tag without calling some kind of scripting language that automates code reuse? There really aren't that damn many reasons to use the <nav> tag for code that isn't going to be reused on multiple pages throughout a site.
And I dunno, I'm sure somebody's brought this up, maybe it's on the itinerary as a consideration for HTML6.
Which is another thing, really: the people making the decisions on the specs do not want the same things I want.
I liked XHTML. (In fact, lest this whole thing come off as a curmudgeonly damn-kids-get-off-my-lawn diatribe against new technologies and standards, I'd like to note that I was using XHTML Strict back when you pretty much had to be using a beta version of Phoenix -- before it was Firebird, before it was Firefox -- for it to render correctly.) I thought it was the future. I wish XHTML2 had taken off. HTML5 feels ugly and inconsistent by comparison, and, as legitimately goddamn useful as it is to be able to put something like data-reveal aria-hidden="true" in the middle of a tag's attributes, it always feels dirty somehow.
But I digress.
Point is, in 2006, I switched the blog from just plain old HTML and CSS, and added two more elements: a MySQL database to actually store all the shit, and a PHP CMS (originally b2evolution, later switched to WordPress).
And then came smartphones.
We live in a world now where every website has to be designed for multiple layouts at multiple resolutions. You wanna try doing that without using an existing library as a base? Try it for a few days. I guarantee you will no longer want that.
I think my resistance to picking up new libraries is that every time you do it, you cede a measure of control for the sake of convenience. I don't like ceding control. I like my website to do what the fuck I tell it to, not what some piece of software thinks I want it to.
I've spent the last decade arguing with blogging software to get it to quit doing stupid shit like turn my straight quotes into "smart" quotes and my double-hyphens into dashes. Just the other day, I built a page in WordPress and discovered that it replaced all my HTML comments with fucking empty paragraphs. Why would I want that? Why would anyone want that?! And that's after I put all the remove_filter code in my functions.php.
And that's the thing: WordPress isn't built for guys like me. Guys like me use it, extensively (it is the world's most popular CMS), because it automates a bunch of shit that we'd rather not have to deal with ourselves and because when we're done we can hand it off to end users so they can update their own site.
But I still write these posts in HTML. I want to define my own paragraph breaks, my own code tags, the difference between an <em> and a <cite> even though they look the same to an end user.
(And okay, I still use <em> and <strong> over <i> and <b>; there's really no explaining that except as a ridiculous affectation. I recently learned Markdown and used it to write a short story -- I'll come back to that at a later date -- and I could see switching to that. HTML really is too damn verbose.)
...and that was another lengthy digression.
So. Mobile design.
Bootstrap is the most commonly used toolkit for responsive websites. I've used it, it works well, but it's not my favorite idiom, and I've decided I prefer Zurb Foundation. So that's what I used to build the new site layout.
Except, of course, then you've got to get two dueling design kits to play nice to each other. Square the circle between WordPress and Foundation.
I started to build the new theme from scratch, and I'm glad I was only a few hours into that project when I discovered JointsWP, because that would have been one hell of a project.
JointsWP is poorly documented but has proven pretty easy to pick up anyway.
So. I've gone from HTML and CSS to HTML, CSS, and WordPress (HTML/CSS/PHP/MySQL), to HTML, CSS, WordPress, Foundation (HTML/SCSS/JavaScript, importing libraries including jQuery), and JointsWP (ditto plus PHP). And on top of that I'm using Git for version tracking, Gulp to process the SCSS, and Bower to download all the other scripts and toolkits I need and keep them updated.
So, going with Foundation (or Bootstrap, or whatever) as a standard toolkit, you get somebody else's codebase to start from. That comes with some elements that are a necessary evil (I hate fucking CSS resets, and think writing p { margin: 0; } is an abomination in the sight of God and Nature -- but if it means I can assume my site will look more or less correct in Mobile Safari without having to go out and buy an iPhone, then I guess I'll take it), and others that are actually pretty great -- I find SCSS to be really exciting, a huge saver of time and tedium, and it's hard to go back to vanilla CSS now that I've used it.
Course, with increasing complexity, you still hit those things that don't quite work right. One example I've found is that Foundation sets your placeholder text (the gray letters that appear in an "empty" input field) too light to be legible, and does not have a simple definition in _settings.scss to let you adjust it to darker. I've found a mixin that allows you to create such a definition pretty simply, but for some reason JointsWP doesn't like it (or maybe Gulp doesn't). So until I get around to finding a fix, the text stays light, and I'll just have to trust that you the user will be able to determine that the input field under the phrase "Search for:" and to the left of the big blue button that says "Search" is a search box.
I've also got loads of optimization still to do; part of that's going to mean figuring out what parts of Foundation's CSS and JS I'm not actually using and cutting them out of the calls, and part of it's probably going to mean minification.
Minification is one of those things I resisted for awhile but have come around on. It can be a real hassle for debugging, not being able to view a stylesheet or script in full, and it may not be practical just to save a few kilobytes (or a few dozen, rarely a few hundred) -- but on the other hand, well, it's not so different from compiling source code to binary; the end result is still that you take something human-readable and turn it into something much less human-readable.
And of course now that I'm using a preprocessor, my CSS file isn't my real source code anyway; it's already the result of taking my code, feeding it through an interpreter, and outputting something that is not my code. If you want to look at the stylesheet for this site, you want to look at the SCSS file anyway (it's on Github), not the CSS file. And if I'm already telling people "Look at the SCSS file, not the CSS file," then what's the harm in minifying the CSS file and making it harder for people to read?
For now -- prior to removing unnecessary code calls and minifying everything -- I feel like the site design's a lot more bloated than it needs to be. And even once I slim it down, there are going to be some compromises that go against my sensibilities -- for example, when you loaded this page, you loaded two separate navigation systems, the desktop version (top navigation and sidebar) and the mobile version (just a sidebar, which contains many of the same elements as the topnav and sidebar from the desktop version but is not exactly the same), even though you can only see one of them. That redundancy makes me wince a little bit, but ultimately I think it's the best and simplest way of doing it. Sometimes, good design does require some redundancy.
All that to say -- man, there have been a lot of changes to web design in the last twenty years. And while there are trends I really don't like (if I never have to build another slideshow it'll be too soon; gradients are usually dumb and pointless; and the trend of making visited links the same color as unvisited ones feels like a step backward into 1995), there are also a lot that I've eventually warmed up to, or at least accepted as something I've gotta deal with.
Anyway. Welcome to the new corporate-sellout.com.
And one more thing about the site before I go: it's probably worth noting that this site is different from the other sites I build, because it's mine. Its primary audience is me. I like having an audience, but frankly I'm always a little (pleasantly) surprised whenever anyone actually tells me they enjoyed something I put on this site.
Because this site isn't one of my professional sites. I didn't build it for a client. It's not my portfolio site, which I built to attract clients. This one? It's for me. As should be clear from this rambling, 2200-word stream-of-consciousness post about the technical ins and outs of web design, as it applies specifically to me and to this site.
Frankly I'm always surprised when anyone actually reads anything like this.